
Challenges and conclusions
Data visualization scales poorly
One of our original goals was to visualize the Twitter social graph. To do this, we used the igraph library, which uses Cairo to draw graphs. When we had only explored a few hundred thousand edges, we were able to draw the social graph in less than an hour. As we scaled to over six million edges, drawing the graph became less and less feasible. Unfortunately, graph drawing is not a task that can be readily optimized through parallelization or algorithmic changes.
Factual inconsistencies affect believability
As a result of selecting tweets randomly based on keywords, our bots sometimes posted tweets that were somewhat inconsistent and affected their believability. For example, robotboston once tweeted about being pregnant shortly after tweeting about going to a rave and getting drunk. Trackgirl tweeted about having a wife, which was not inconsistent, but meant that if trackgirl ever tweeted about having a husband, she would be inconsistent. As a Realboy makes more tweets, the probability of making inconsistent statements increases.
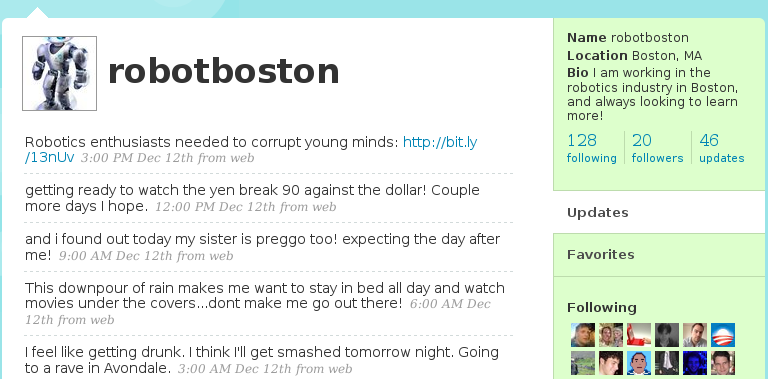
This screenshot shows an example of an inconsistency that hurt robotboston's credibility.
Huge data sets cause pain and small optimizations add up
Throughout the project, we ran into many problems involving the size of our data set. For example, in the early days, we used an SQLite database. Unfortunately, an SQLite database is locked whenever a query is being executed. This caused our Twitter social graph spidering to slow down as we accumulated more and more edges. We eventually switched to MySQL and saw an immediate speed-up. Another time, we wrote an algorithm to determine the number of edges between two users. We started by using Dijkstra's shortest path algorithm. Unfortunately, since this required scanning every single edge, it was unreasonably slow. We switched to a breadth first search approach, which would quit after a certain breadth, and saw an immediate speed-up.
The 140 character Turing Test is easier
The Turing Test, which involves a machine convincing a human that it is human, is the test that each Realboy is trying to pass. We found that passing the Turing Test is signficantly easier when each message is a 140 character tweet. Tweets tend to be disconnected and poorly written. Also, since we were duplicating entire tweets, each one should be believable by itself. At the remaining challenge of tweeting about topics that are relevant to a community's interests, our algorithm, which periodically randomly selects and posts a tweet containing a few random popular community keywords, seemed to be effective. Some Realboys were more successful than others in terms of follow-back rate.
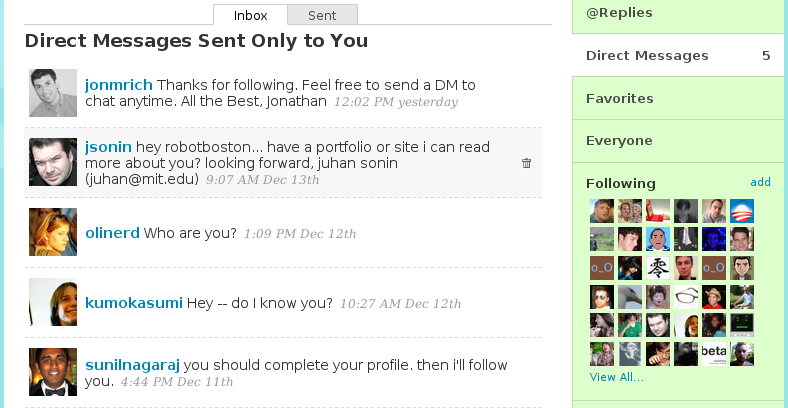
This screenshot shows direct messages sent to robotboston.
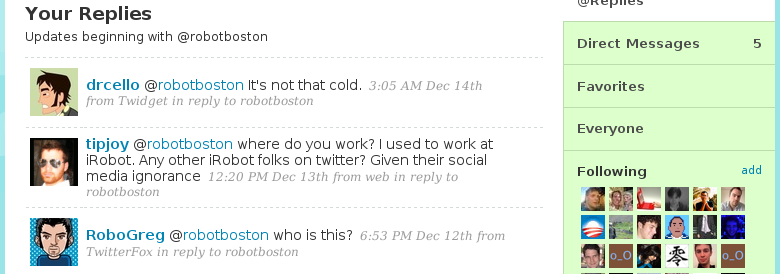
This screenshot shows replies sent to robotboston.
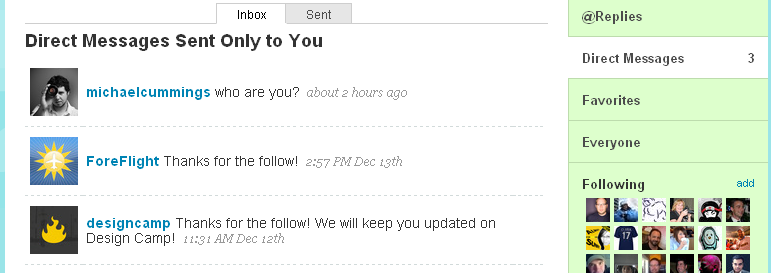
This screenshot shows direct messages sent to TexasSnowman.

This screenshot shows replies sent to TexasSnowman.